
You can’t feel it, you can’t see it, you can’t touch it, but unplanned work is silently killing your business. How many times have you finished your day at work, very exhausted yet unable to cross anything off your list of high-priority to do things? This can make you feel robbed. It is impossible to tell where your time went to. This is a sign that you are falling victim to unplanned work.
Unplanned work is not evident in our metrics of performance, so it is difficult to analyze. However, the impact of unplanned work is great. It can mask dependencies and block and stall important priorities. Risk will accumulate across your system if you receive more work and start it late. The risk will continue to yield more risks in the form of unknown dependencies, neglected work, too much WIP and conflicting priorities. This can jeopardize the ability of your organization to deliver predictably.

Effects of Unplanned Work
You can encounter unplanned work in 2 different flavors:
- The requirements that you have to change in the middle of a project
- The defects you find during testing.
You can deal with both of them if you have an agile team that is run well. It is important to understand the cause of unplanned work if you want to make your project cheap and predictable.
It is also important to understand that unplanned work steals valuable time from planned work. Most people see unplanned work as a norm instead of seeing it as a significant problem.

When solving a problem, you should ensure that the problem will not occur again, but if you solve the symptoms of a problem rather than the problem, then the problem is likely to occur again. The main problem that is left unattended will lead to more issues which will lead to the allocation of more resources, and this can worsen things.
Every organization, department, team, and individual should measure the amount of unplanned work that is being performed. You can even forget about solving problems that come later and get a sense of how much time is allocated to work that isn’t adding any value to the business and rather spent on fighting the status quo.
Let us consider release management as a concrete example to explain unplanned work. You take a piece of software and deploy it to the market and spend a lot of time trying to diagnose why a certain release didn’t work as expected. The time you spend trying to diagnose the problem is unplanned work. You can easily solve some of these issues through deployment, continuous integration and automated testing. You can be proactive and resolve a lot of (future) unplanned work as you try to diagnose and debug why things didn’t work as you had expected.
It is difficult to get rid of unplanned work, but we can easily learn how to plan for it. The only concern is how to plan and tackle unplanned work. Before we go deep and discuss how you can handle and mitigate unplanned work, it is important to discuss incident management, problem management, and post-mortems because they can help plan for the unplanned.
Incident Management and Problem Management
Problem management and incident management are key components of the Information Technology Infrastructure Library service model, and they have been created to provide a more streamlined service to consumers.
Incident Management
Incidents are things related to customer contacts. They can be account updates, information request, and issue reporting. There are different methods that incidents can be reported through, and this includes email, phone, and chat. Incidents can also be generated by automatic monitoring tools. There are different incidents that come through/from different sources. They would get routed to your tool for incident management. This could be something simple for smaller teams, but larger teams may need enterprise level tools or in-house customer-built applications.
Your business should have the responsibility of reviewing information about different incidents and check if there is a solution available to the customer. An example of an incident is when a customer wants to change their account password. The helpdesk will receive the incident, get the necessary information and make sure the customer has passed all the security checks, facilitate the changing of the password and inform the customer that the password has been changed and then close the incident. Some incidents can be managed with automatic tools while others have to be managed manually.
Problem Management
Incident management is repetitive in nature and can get tedious. This can exhaust the more skilled employees in your organization so if you have such employees in your organization, consider moving them into managing problems.
Problem management is deeper than incident management. This is where a single problem causes multiple incidents from multiple clients or customers. Problem management needs the best people. The role of these people is to find out why a certain problem happened and find the best ways to fix it and prevent the problem from happening again.
Post-mortem
A post-mortem is usually performed after a project has been concluded. The process helps to determine and analyze different elements of the concluded projects that were successful or unsuccessful. The main purpose of project post-mortem is to inform improvements in processes to mitigate future risks. This helps to promote best practices in an organization. Post-mortem helps to manage risks in an organization.
Mitigating unplanned work
As we had already seen, unplanned work is time-consuming, expensive and can negatively impact other projects in your organization.
It can also drain all your skilled resources. This can be the rarest and the most important resources you have in your organization. This is why unplanned work hurts more. Two main methods you can use to mitigate unplanned work are:
- Widening the bottleneck to moving configurations down and upstream without having to tie down your constrained skill base.
- Increasing communication flow between producers and developers to relevant changes.
When you widen the bottleneck, it turns hours of work into a few minutes. If something goes wrong, you can always roll back and mitigate the impact of unplanned work. You can widen the bottleneck by creating a build of configurations, automating activities of migration of configurations and creating other jobs.
When the flow of communication is increased, your developers will know any changes to production that impacts their activities directly. They will be able to run comparisons instantly against critical systems and see if they have to consider specific changes as they perform their work. This helps to prevent failed deployments or reduce the likelihood of failed deployments.

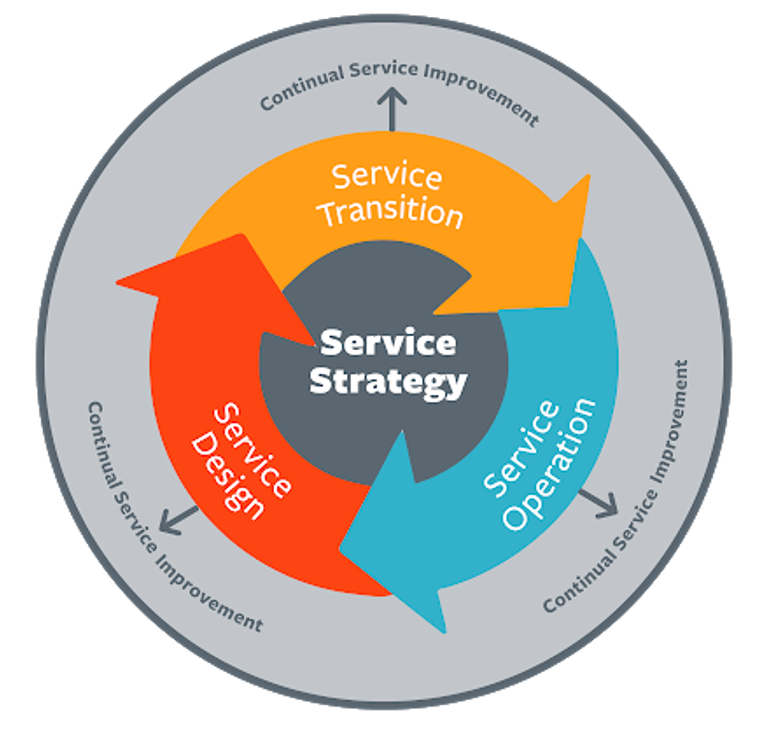
Customer relationship management
{kind=link}
This is somewhat self-explanatory. Customer relationship management (CRM) is a strategy used by a business to execute business objectives and meet the requirements of their customers.
The service strategy can be used to improve the customer relationship strategy within a business and ensure that the business can create value for its shareholders and customers by contributing to the value. The strategy ensures that businesses are able to organize their operations in an appropriate manner to deliver services that will enable the success of customers.

Document Objectives
The business objectives are the results you want to maintain and achieve as you run your business. Every business should have clear and attainable goals.
The goals may include productivity, profitability, customer service, core values, employee retention, growth, change management, marketing, maintain financing, competitive analysis and more.
Document Requirements
If you want to arrive at a solution that will ensure the continuity of your business, you need to map out every application; server, data, and software solution set in your environment. You should assign a downtime tolerance that is business-driven for each of the requirements. Map out the application interdependencies as you do this.
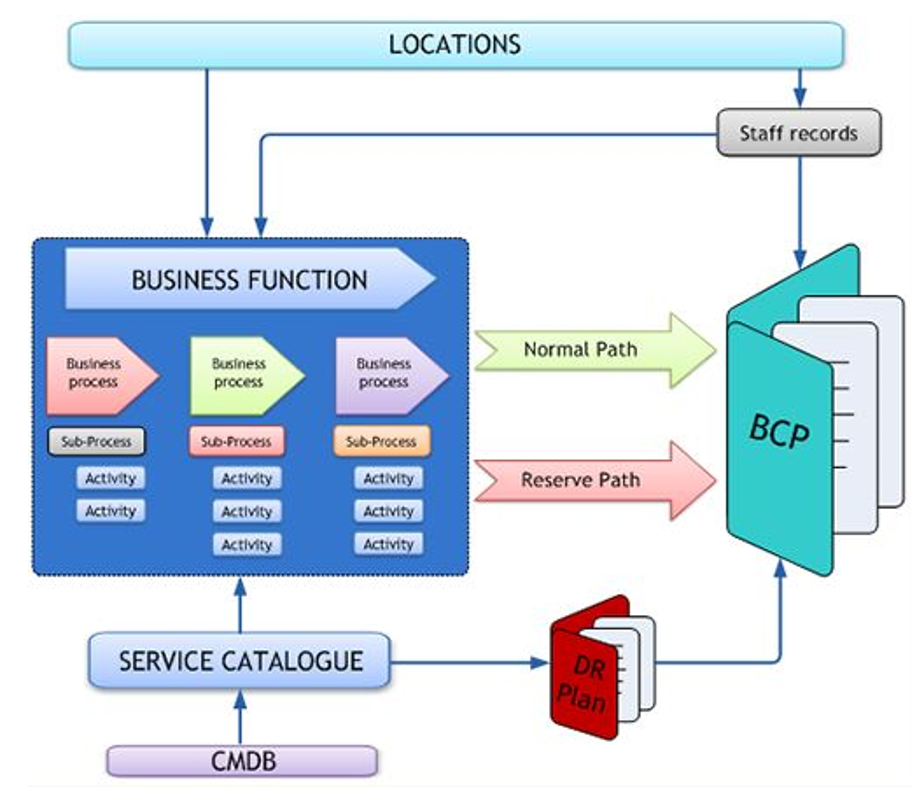
Test Your DR Planning
Disaster Recovery is never a onetime event. This is a constant process, and it is important for disaster recovery to keep up with the changes in the environment and evolving service-level agreements. The truth is that the data center is rapidly changing and it is almost impossible for the change control processes and operations to keep up. It is also very hard to conduct disaster recovery tests with enough frequency to be meaningful. This leads to most companies considering disaster recovery and tools for monitoring to allow analysis that is a near-real-time of the disaster recovery processes and setup.
Every business should conduct disaster recovery tests to determine the people who need more training and also know the disaster recovery processes that need to be refined. Some of the main disaster recovery things that a business should have include monitoring, environment awareness, hardware, and software independence and work from a knowledge base.